Java Call Function Again if Failed
This browser is no longer supported.
Upgrade to Microsoft Border to take reward of the latest features, security updates, and technical back up.
Retry pattern
Enable an application to handle transient failures when it tries to connect to a service or network resources, past transparently retrying a failed operation. This can amend the stability of the application.
Context and problem
An application that communicates with elements running in the cloud has to be sensitive to the transient faults that can occur in this environment. Faults include the momentary loss of network connectivity to components and services, the temporary unavailability of a service, or timeouts that occur when a service is busy.
These faults are typically self-correcting, and if the action that triggered a fault is repeated afterward a suitable delay it's probable to be successful. For example, a database service that's processing a large number of concurrent requests can implement a throttling strategy that temporarily rejects any farther requests until its workload has eased. An awarding trying to access the database might fail to connect, just if information technology tries again later a delay it might succeed.
Solution
In the cloud, transient faults aren't uncommon and an awarding should exist designed to handle them elegantly and transparently. This minimizes the furnishings faults can take on the business tasks the application is performing.
If an application detects a failure when information technology tries to ship a request to a remote service, it can handle the failure using the following strategies:
-
Cancel. If the mistake indicates that the failure isn't transient or is unlikely to be successful if repeated, the application should cancel the operation and report an exception. For case, an authentication failure caused by providing invalid credentials is not likely to succeed no affair how many times information technology's attempted.
-
Retry. If the specific error reported is unusual or rare, it might accept been caused by unusual circumstances such as a network bundle becoming corrupted while information technology was being transmitted. In this example, the awarding could retry the failing asking again immediately because the same failure is unlikely to be repeated and the request volition probably be successful.
-
Retry later on filibuster. If the fault is caused by one of the more commonplace connectivity or busy failures, the network or service might need a short menstruation while the connectivity issues are corrected or the excess of work is cleared. The application should await for a suitable time before retrying the request.
For the more common transient failures, the menses between retries should exist chosen to spread requests from multiple instances of the application as evenly as possible. This reduces the risk of a busy service continuing to exist overloaded. If many instances of an application are continually overwhelming a service with retry requests, it'll have the service longer to recover.
If the asking notwithstanding fails, the application can expect and make another endeavour. If necessary, this process can exist repeated with increasing delays between retry attempts, until some maximum number of requests take been attempted. The delay can be increased incrementally or exponentially, depending on the type of failure and the probability that it'll be corrected during this time.
The following diagram illustrates invoking an performance in a hosted service using this design. If the request is unsuccessful after a predefined number of attempts, the awarding should treat the fault as an exception and handle information technology appropriately.
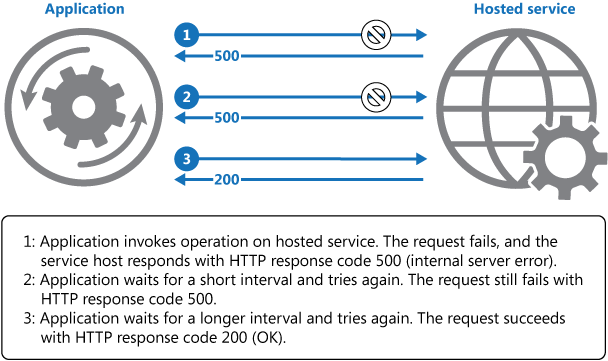
The application should wrap all attempts to admission a remote service in code that implements a retry policy matching 1 of the strategies listed higher up. Requests sent to unlike services can exist subject to unlike policies. Some vendors provide libraries that implement retry policies, where the application can specify the maximum number of retries, the time between retry attempts, and other parameters.
An awarding should log the details of faults and failing operations. This information is useful to operators. That beingness said, in order to avert flooding operators with alerts on operations where subsequently retried attempts were successful, it is all-time to log early failures as advisory entries and merely the failure of the terminal of the retry attempts as an actual fault. Here is an example of how this logging model would look like.
If a service is ofttimes unavailable or busy, it's often because the service has exhausted its resources. You can reduce the frequency of these faults by scaling out the service. For example, if a database service is continually overloaded, it might exist beneficial to partition the database and spread the load across multiple servers.
Microsoft Entity Framework provides facilities for retrying database operations. Too, nearly Azure services and client SDKs include a retry mechanism. For more information, encounter Retry guidance for specific services.
Bug and considerations
You lot should consider the following points when deciding how to implement this pattern.
The retry policy should exist tuned to match the business requirements of the application and the nature of the failure. For some noncritical operations, it'due south better to fail fast rather than retry several times and bear upon the throughput of the awarding. For example, in an interactive web application accessing a remote service, it'southward better to fail later on a smaller number of retries with only a short filibuster between retry attempts, and brandish a suitable message to the user (for instance, "delight try again later"). For a batch application, it might exist more appropriate to increase the number of retry attempts with an exponentially increasing delay between attempts.
An aggressive retry policy with minimal delay between attempts, and a big number of retries, could further degrade a decorated service that'due south running close to or at capacity. This retry policy could besides touch on the responsiveness of the awarding if it'southward continually trying to perform a failing functioning.
If a asking still fails after a significant number of retries, it'south better for the application to prevent further requests going to the same resources and simply report a failure immediately. When the period expires, the application tin can tentatively allow one or more requests through to see whether they're successful. For more than details of this strategy, run into the Circuit Breaker pattern.
Consider whether the performance is idempotent. If so, it'southward inherently safe to retry. Otherwise, retries could crusade the operation to be executed more than than once, with unintended side furnishings. For example, a service might receive the asking, procedure the request successfully, just fail to send a response. At that point, the retry logic might re-send the request, bold that the outset request wasn't received.
A asking to a service can fail for a variety of reasons raising different exceptions depending on the nature of the failure. Some exceptions indicate a failure that can be resolved rapidly, while others point that the failure is longer lasting. It'south useful for the retry policy to adjust the time between retry attempts based on the type of the exception.
Consider how retrying an operation that'due south part of a transaction will bear on the overall transaction consistency. Fine tune the retry policy for transactional operations to maximize the chance of success and reduce the demand to disengage all the transaction steps.
Ensure that all retry code is fully tested against a diverseness of failure conditions. Check that it doesn't severely impact the performance or reliability of the application, cause excessive load on services and resources, or generate race atmospheric condition or bottlenecks.
Implement retry logic just where the full context of a failing operation is understood. For example, if a task that contains a retry policy invokes another task that also contains a retry policy, this extra layer of retries can add long delays to the processing. It might be better to configure the lower-level job to neglect fast and report the reason for the failure back to the task that invoked it. This higher-level task tin can then handle the failure based on its own policy.
It'southward of import to log all connectivity failures that cause a retry then that underlying problems with the application, services, or resources can be identified.
Investigate the faults that are most probable to occur for a service or a resource to detect if they're likely to be long lasting or final. If they are, information technology's meliorate to handle the fault as an exception. The application tin can report or log the exception, and and so try to continue either past invoking an alternative service (if ane is available), or by offering degraded functionality. For more data on how to detect and handle long-lasting faults, run into the Circuit Billow pattern.
When to apply this pattern
Employ this pattern when an awarding could experience transient faults as information technology interacts with a remote service or accesses a remote resources. These faults are expected to be short lived, and repeating a request that has previously failed could succeed on a subsequent attempt.
This pattern might not be useful:
- When a fault is likely to be long lasting, because this can bear upon the responsiveness of an awarding. The application might be wasting fourth dimension and resources trying to echo a request that's likely to fail.
- For handling failures that aren't due to transient faults, such as internal exceptions caused by errors in the concern logic of an application.
- Equally an culling to addressing scalability issues in a organization. If an awarding experiences frequent busy faults, it'south often a sign that the service or resources being accessed should be scaled up.
Example
This instance in C# illustrates an implementation of the Retry blueprint. The OperationWithBasicRetryAsync method, shown below, invokes an external service asynchronously through the TransientOperationAsync method. The details of the TransientOperationAsync method will be specific to the service and are omitted from the sample code.
individual int retryCount = three; private readonly TimeSpan filibuster = TimeSpan.FromSeconds(5); public async Task OperationWithBasicRetryAsync() { int currentRetry = 0; for (;;) { try { // Call external service. await TransientOperationAsync(); // Return or break. break; } catch (Exception ex) { Trace.TraceError("Operation Exception"); currentRetry++; // Cheque if the exception thrown was a transient exception // based on the logic in the error detection strategy. // Determine whether to retry the operation, besides as how // long to await, based on the retry strategy. if (currentRetry > this.retryCount || !IsTransient(ex)) { // If this isn't a transient error or we shouldn't retry, // rethrow the exception. throw; } } // Expect to retry the operation. // Consider calculating an exponential filibuster here and // using a strategy best suited for the performance and fault. await Job.Delay(delay); } } // Async method that wraps a call to a remote service (details not shown). individual async Chore TransientOperationAsync() { ... } The statement that invokes this method is independent in a try/grab block wrapped in a for loop. The for loop exits if the telephone call to the TransientOperationAsync method succeeds without throwing an exception. If the TransientOperationAsync method fails, the catch cake examines the reason for the failure. If it's believed to be a transient error the code waits for a short delay before retrying the operation.
The for loop as well tracks the number of times that the operation has been attempted, and if the code fails three times the exception is assumed to be more than long lasting. If the exception isn't transient or it's long lasting, the grab handler throws an exception. This exception exits the for loop and should exist caught past the code that invokes the OperationWithBasicRetryAsync method.
The IsTransient method, shown below, checks for a specific set up of exceptions that are relevant to the environment the code is run in. The definition of a transient exception volition vary according to the resources being accessed and the environment the operation is beingness performed in.
private bool IsTransient(Exception ex) { // Determine if the exception is transient. // In some cases this is as simple equally checking the exception type, in other // cases information technology might be necessary to inspect other backdrop of the exception. if (ex is OperationTransientException) return true; var webException = ex as WebException; if (webException != null) { // If the web exception contains one of the following status values // it might exist transient. return new[] {WebExceptionStatus.ConnectionClosed, WebExceptionStatus.Timeout, WebExceptionStatus.RequestCanceled }. Contains(webException.Status); } // Additional exception checking logic goes here. render false; } Next steps
-
For almost Azure services, the customer SDKs include built-in retry logic. For more than data, see Retry guidance for Azure services.
-
Before writing custom retry logic, consider using a general framework such as Polly for .NET or Resilience4j for Java.
-
Circuit Breaker blueprint. If a failure is expected to be more long lasting, information technology might exist more advisable to implement the Circuit Breaker pattern. Combining the Retry and Circuit Billow patterns provides a comprehensive arroyo to handling faults.
-
When processing commands that change business data, be aware that retries can result in the activity beingness performed twice, which could be problematic if that action is something similar charging a customer's credit card. Using the Idempotence design described in this blog post can help deal with these situations.
Feedback
Submit and view feedback for
Source: https://docs.microsoft.com/en-us/azure/architecture/patterns/retry
0 Response to "Java Call Function Again if Failed"
Post a Comment